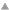This makes iterating over a given table just like iterating over the corresponding association list
That's a cool point!
If calling a list wasn't already doing a lookup by position, I might like a call on a cons to do an alref so that I could use x!foo to do a lookup by 'foo whether x was a table or an assoc list.
I had said: "You can first use Git to develop a library using Git as a version control system and then publish your library using Git in my approach. However you can't use the same commit for both: you can't take a commit that has version control type ancestors and publish it as a dependency type commit. Instead you have to create a new commit which has only prerequisite hacks as ancestors."
Actually, I think I was wrong about that. At first I thought I was doing something completely different than normal Git practice, now it looks like it may be more of a tweak.
The end-programmer can use tags to list out the hacks being used (the prerequisite hacks), and so it doesn't matter how many commits there are between tags. If you tag your library "yourname.lib-foo-v1", then have a whole bunch of development history, and then tag the next release as "yourname.lib-foo-v2", that works fine. Which is standard Git practice.
The important thing is that once you've publicly published a hack with some ancestor commit, that you always include that ancestor commit. For example, it won't work to say, "hmm, for v3, I don't need all that old development history that I published with v2, so I'll publish a clean patch series that has commits only for the changes between v1 and v2, and between v2 and v3". That will break the merge when the end-programmer tries to merge your v3 on top of the v2 copy they have.
It is OK to privately develop a library, see that you have a messy development history, and then decide you want to publicly publish a commit that has only the differences from your previously publicly published version. The trick is whatever commits you've made public in the past, you keep as ancestor commits as you move forward.
Having separate meaning, determined by context, means that you don't have to use as many distinct identifiers in your program. This is especially pronounced if you're trying to use short identifiers, because there are fewer short identifiers that have some intuitive meaning attached to them, and I think it's useful to allow context to alter this meaning.
However, now that I think of it a bit more, making Arc a Lisp-2 would interfere with using compound data in the place of functions. If you have a symbol whose value is a compound type, and that symbol also has a function value, that creates an ambiguous situation. I'll have to suspend my opinions about Lisp-n-ness until I've used Arc for a while.
I'm a big fan of using identifiers such as 'list, 'string, 'fn (isn't a problem in CL, but is one in Arc), 'array, 'char, etc. Often a general name is the most concise and appropriate name to use.
I think that since Arc is supposed to be designed towards flexibility and usability for the programmer, it should have few restrictions, and a common namespace is such a restriction.
However, my opinion on this could change as I explore Arc over the next few weeks.
I added a section about how to include a previous commit as a parent of your commit without including any of the previous commit's code.
An example of when you'd need to do this is when you're publishing a fix which replaces some previous fix and doesn't use any of its code, and you want Git to use your fix instead of the previous one.
oh, you're storing the default value inside the hash table itself. It took me a while to figure out what you were doing.
If you store the default value outside of the table then it won't show up when we print out the table, look at its keys, iterate over its keys and values, call tablist on it etc.
For example, you could store all the table defaults in its own hash table, using the tables as the keys and the default values as the values of the table: