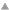testible.clef means look up the value stored at what clef evaluates to in testible
testible!clef means look up the value stored at clef in testible
testable.0 means look up the value stored (at what 0 evaluates to) in testible
testible!0 means look up the value stored at 0 in testible
atist.0 means look up the value stored at what 0 evaluates to in atist
atist!0 means look up the value stored at 0 in atist
0 of course being an atom evaluates to 0
but what if you want it to evalute to something like the key stored at 0 . . .
. . . if quote means something like "don't evaluate" and unquote means something like "do evaluate" then one could reason that
atist,0 means look up the value stored at what 0 evaluates to (do evaluate it) in atist
! and . behave the same with alists and numbers while its inconvenient if you want to access the key it makes sense.
Is this reasonable?
Edit: this could work for alists and insertion-ordered tables since it's unobvious how testible!0 & testible.0 should behave, numbers can and should be able to be keys so one can imagine a situation where behavior would be like so:
It's only more memory efficient than its previous incarnation.
It's an interesting implementation though. The use of sparse arrays to index the entries is compelling. Measuring this kind of stuff can be non-trivial though as you also have to account for gc (and/or compaction) at different times within your application. There are always trade-offs.
Personally I haven't compared the various implementations (clojure vs. racket vs. python) such that I can give you any real insight. I know clojure's (or rather java's) array-maps are costly when performing iterative lookups within large data sets because I've benchmarked it.
The best bet is to see how an implementation works for your app with your data.
I agree with some of your first point, but the second not so much. I think pg released arc as a first cut with one application baked in to act as marker for a stable version. Obviously I can only guess, but I also think he expected a larger community of interest, one that could take it to the next level. That never happened and with only a handful of keeners, 10 years later, the things you mention in your first point are non-existent or half-baked experiments. It's possible Arc may get there, and I hope it does, but at this rate it may take a hundred years. :)
More interestingly, though, shawn is bringing some interest back (at least for me) and making substantial changes that could breathe new life into Arc. I don't agree with the empty list - nil change, but the table changes and reader changes are good. I do think the more seamless the racket interop is and the more racket can be leveraged, the better. Clojure has good interop with java and that's what made Clojure explosive. If we can do that with Arc/Racket then we are better off for it.
I agree; an empty list is a value. And when you consider interop with other langs, they will infer it to be some object too, where predicates will see it as a value not the lack of one.
IMH and unqualified O, I think that what holds back widespread Arc adoption (other than the existence of Clojure) are lack of effective namespacing and unhygienic macros, which make modular code and things like proper package management/libraries infeasible if not impossible. Also, the way the dependencies in news are engineered make it very difficult to disentangle or update what has become an obsolescent web application from the core language without risking breaking everyone else's code.
Ironically I've found (others may feel differently) that while pg may have wanted the purpose of Arc to be exploratory programming, he seems to have done so with a number of his own assumptions baked in to the language, implicitly limiting exploration to what he considers to be correct, and to what correlates with his personal style. It's like Arc is Henry Ford's Model T: you can have it in any color you like, as long as you like black.
But changing these aspects of Arc would make it no longer Arc, at least philosophically.
But why should an empty list be falsy? An empty list can be as valid a form of list as a non-empty one. It also seems to me that an empty list shouldn't be nil, since to me, nil should mean "undefined", and an empty list is well defined as an empty list.
Would disambiguation here really make Arc programs less terse? Is that a decision that should be enforced by the language or left to the author?
and ar-nil is falsy. So your example will work unmodified.
... oh. And now that I check, you're right about void:
arc> (seval '(if (void) 1 2))
1
I foolishly assumed that (void) in racket is falsy. But it's truthy. That rules out using racket's (void). `(null ? 1 : 2)` gives 2 in JS, and `if nil then 1 else 2 end` gives 2 in Lua, so it's surprising that `(if (void) 1 2)` gives 1 in Racket.
For what it's worth, in an experimental version, using #f for ar-nil and #t for ar-t worked. It's a bit of a strange idea, but it helps interop significantly due to being able to pass arc predicates right into racket.
It'd be better for me to show a working prototype with ar-nil set to #f rather than try to argue in favor of it here. But to your original question: yes, anything other than |nil| would be great, since that gets rid of the majority of interop headaches.
One thing that might be worth pointing out: The lack of void means it's back to the old question of "how do you express {"a": false, "b": []} in arc?" Choosing between #f and () for nil implies a choice between forcing {"a": false} or {"b": []} to be the only possible hash table structures, since one of them would be excluded from hash tables. But that might be a tangent.
Yes, the keyword section was poorly explained. My comment should have been prefixed with "some thoughts on arc, in case it's helpful" rather than "here is a proposal." And then I should have taken that comment and put it in a different thread, since keyword arguments are unrelated to the question of nil becoming (). I was mostly just excited for the possibility of leveraging more racket now that denil/niltree might be cut soon.
This is off-topic but pg is shockingly Eurocentric, he seems from that excerpt to be completely oblivious to or completely willing to elide the generations of advances made in almost every field by the luminaries of the muslim empires including things like . . . ALGEBRA!
Not quite. The distinction I'm drawing is between ordering the elements based on their intrinsic properties, and ordering the elements based merely on the order they're inserted in.
Arguably it's an interesting failed experiment. But unfortunately that was not the conclusion Aristotle's successors derived from works like the Metaphysics. [9] Soon after, the western world fell on intellectual hard times. Instead of version 1s to be superseded, the works of Plato and Aristotle became revered texts to be mastered and discussed. And so things remained for a shockingly long time. It was not till around 1600 (in Europe, where the center of gravity had shifted by then) that one found people confident enough to treat Aristotle's work as a catalog of mistakes. And even then they rarely said so outright.
If Arc is to attain widespread adoption – an aim we're focusing on with laarc – I believe that it will need to transition away from the rigid abstractions of the past and give users what they want: true, false, empty list, and a value that means "undefined". Lua calls this nil.
JS also has a value called null. It's very useful to use null as a placeholder. Without null, it's probably impossible to differentiate between calling an arrow function without arguments vs passing in `undefined`. This gave the language flexibility going forward, and gave it an escape hatch that Lua doesn't have: the ability to use a null value as a sentinel value. You'll notice it's quite impossible to store nil in tables in Lua. (It's ... not strictly impossible, but it makes interop with libraries a nightmare.)
Users need JSON. JSON has true, false, null, strings, numbers, arrays, tables, and empty arrays.
Users also want to work with existing libraries. They don't want FFI wrappers. There's just no time for any of that when you're in a mad dash for hammering out features. It's partly why pg gave up on working on the core language and focused solely on HN for some years.
To that end, I propose several changes:
- the result of a predicate is either false or something other than false. This gives us interop with Scheme, because that means we can e.g. pass (fn (a b) (< a.0 b.1)) to racket's SORT function as the comparator, and everything will work fine. We don't get this now, because of the t/nil constraints.
- The result of (if false 'foo) is void, not false. This gives users an explicit way to avoid boolean values in the cases that it matters. Which is rarely, but those rare cases can be excruciating without this.
- The value of the symbol t is changed to #t. This works fine out of the box right now.
- The value of the symbol nil becomes void, not an empty list. (I need to research this one, but I am ~70% confident it can work.)
- car, cdr, and cons are updated to work with the above. I have already done this in a fork of laarc and know this is the key that makes all the other pieces fall in place.
There are many advantages of this model. One is that you'll get the entire racket ecosystem basically for free. It can be up to users whether to rely on racket or whether to stick with pure Arc. (Arc itself should probably stay away from using Racket so as to ease porting the language, but it's a blurred line to decide what counts as "core arc" vs "libraries supporting arc". That said, users need Racket features, and need to be able to evaluate racket code on demand to use these features.)
Another advantage is keyword arguments. This is one of my primary areas of research with respect to arc, and I have a prototype version that handles common cases. It will take some legwork to handle all of the cases correctly, but this gives users the ability to at least call racket functions via keyword arguments without having to resort to #:foo syntax. (#:foo was an aesthetic mistake; I think the original paper basically says "We polled some users and no one had strong feelings, so we went with this." Good luck typing #:foo into your phone's Arc REPL in under two seconds.
(def sorted (xs (o scorer <) (o :key idfn))
((seval 'sort) xs scorer key: key))
In the above example, :key is a keyword argument. You can call sorted like this:
> (sorted '(c a b))
(a b c)
> (sorted '(c a b) >)
(c b a)
> (sorted '((c 1) (a 0) (b 2)) key: car)
((a 0) (b 2) (c 1))
This gives a way to port a huge quantity of Arc code in news.arc from the old style to the new keyword style incrementally. You can transition each argument over to be a keyword when it makes sense to do so. This sort of gradual evolutionary path is important when introducing fundamental changes.
There is no way to protect users from the fact that if they want to transpile, or they want to interop with existing libraries, and users have no language for expressing the semantics of those interfaces, then those users are mostly screwed and will quietly switch to something more effective.
Arc is the embodiment of an exciting idea: that a modern lisp can be fun, and so powerful that you can run circles around competitors before they understand what's happening. (The "suggest title" feature in laarc is still my favorite thing to point to vs HN.) And the core of that mindset is exploration. If this seems like a good idea, we should transition to it. Choosing to roll back later is always an option, even if it would be a little painful.
But I think we'll find that these features make it possible to handle all of the existing cases in Arc without problems, that things tend to "just work by accident" instead of forcing the user to think through unexpected problems, and that you'll be able to write and ship features very quickly -- and perhaps even to more runtimes than just Racket, like in-browser support for the Arc compiler. You'll notice https://docs.ycombinator.lol/ is basically the Arc library, even though it's illustrating functions from Lumen. (whenlet x 42 (prn x)) works, for example.
Yeah, memory usage was a big reason I stopped trying to maintain servers in Arc (and went down my insane yak-shaving rabbithole of trying to reinvent the entire computing stack from scratch).
Oh yeah, I never posted an update. I finished porting HN to elisp. That project's readme should now be "This is a mostly-complete implementation of Paul Graham's Arc in Emacs Lisp."
It’s wildly hilarious to see HN running in emacs. It loads up all 500 laarc stories and user profiles in a few seconds, which is much lower overhead than I thought. Then you can run `(login-page “foo” ..)` and it spits out all the right HTML. If it weren’t so weird to do networking in elisp it could even become a real server. </hack>
If anyone's curious, here's an email I sent to a friend about this:
--
I finished porting HN to emacs. One advantage of the elisp runtime is that closures have printed representation. That means you can write them, read them, and evaluate after reading. Which implies serialization.
It also means you can deduplicate them. I notice that laarc has 20k fnids. When I deduped the fns* table on my local elisp version of HN, the size of the table went from 49 to 2.
From looking at the closures, I don’t think there is any reason they can’t be persisted to disk and run later. I can’t find any examples of fnids that capture lexical context which mutates before the fnid is called. The lack of mutation is a key point that should enable serialization... I think/hope.
The takeaway is that there doesn't seem to be a reason to get rid of the fnid system as laarc scales. I started doing that for a few endpoints, but it’s crazy how much work it is in comparison to spinning up an fnid. HN has to detect whether a request is a POST or GET, and respond differently. It's good to have that in general -- in fact, every web framework except arc has the ability to differentiate between POST vs GET. But it really speaks to the power of this technique that it's possible to do without!
I need to figure out the easiest thing to do to keep https://www.laarc.io memory usage down as we scale.
HN's server specs are monstrous, and it’s a good reminder that cloud hosting is still limited if you absolutely cannot scale horizontally. Maybe colocation could be the way to go for us later on.
The site’s memory usage has been steadily creeping up — 76mb was the baseline in the early days, and now it’s >100 and <150. That’s a worrying sign. I can bump the droplet from 1gb to 2, and 2 to 4, but that won’t work forever.
I was going to say “This probably won’t be a problem for 6 months or so.” But that’s not true. If laarc gets picked up on techcrunch, I need to be able to handle an infinite amount of traffic. For sufficiently small values of infinity.
Is that really "the simplest things"? :-p It seems to me Arc goes out of its way to avoid interleaving source location information on s-expressions the way Racket does. Putting it back, without substantially changing the way Arc macros are written, seems to me like it would be pretty complicated, and that complication would exist whether Arc was implemented in Racket or not.
Surprisingly it's possible to get pretty close. The trick is to read-syntax rather than read, and then have ac map over syntax objects properly. At that point it's a matter of using eval-syntax rather than eval.
The takeaway is that the error messages are much, much nicer. I'm talking "the error is at line 213 of app.arc in function init-userinfo" nicer.
It's not perfect. And to get to perfect, you'd have to do as you say and rework how macros behave. But it's maybe 90% of the benefit with little work.
> I recommend not expecting `quote` or `quasiquote` to be very useful outside the context of metaprogramming.
My immediate reaction is to disagree. A lot of the reason Lisp is so great is that quasiquotation is orthogonal to macros/metaprogramming.
> ; Should this cause an error, or should it result in the same thing as
> ; '(let i 0 `{,++.i "foo"}) or '(let i 0 `{,++.i "foo"})?
Those two fragments are the same?
In general it feels unnecessarily confusing to include long doc comments in code fragments here. We're already using prose to describe the code before and after.
Code comments make sense when sharing a utility that you expect readers to copy/paste directly into a file to keep around on their disks. But I don't think that's what you intend here?
Finally, both your examples seem to be more about side effects in literals? That is a bad idea whether it's a table literal or not, and whether it uses quasiquoting or not. Do you have a different example to show the issue without relying on side-effects?
I do think the data load for this would always be low.
I feel like implementing tables with indices would basically be like implementing ordered dictionaries (new nomenclature I've arrived at per: http://arclanguage.org/item?id=21037 ), no?
I agree that order matters. It matters in pretty much every application that uses data. Even HN has data ordered by newest, rank (best) etc. And Arc has a tonne of functionality to support sorting and comparing data to let you do that very thing.
But I don't see the need to order data in your application equating to the need for tables that support constant insertion order.
I 'm not going to say what you're doing is wrong because it's not, but I am going to say it's non-standard and I think there other ways to manage your data that doesn't require ordered tables (which have downsides with data growth). It's just my opinion, but there's not much you can't do with the standard storing of table records and maintaining of indexes.
That said if your data load is always low with little to no growth it could very well be a good fit.
Order definitely matters, and I'm envisioning functionality like repeating tasks that once moved to the "done" stack/marked done wrap around to `pipe.0`(Imagine something that must be done once a month or once a week).
I suppose I could tag items as monthly or weekly in which case they'd get appended to pipe!month or pipe!week as soon as they're done.
Another example is the `(createItem)` function which should take an item and an optional "stack" parameter. If no stack parameter items should be appended to the zeroeth stack `pipe.0` identified by index because it will be named by different keys in different pipelines.
Another example is a `(push)` function which pushes an item from its current stage to the "next" stage. With order this is simple.
EDIT: Order even matter matters within a stack. In the current kanban system I have a bunch of things I need to do today, the top priorities are actually at the top. I wouldn't want them getting all disheveled.
> Q: If special syntax support for alists were added would a!k return a keyvalue pair (`assoc`) or just a value(`alref`)?
One option is to extend calling lists so that calling a list with a number would continue to do the same thing (return the item at that position), while calling a list with a non-number would treat the list as an association list and do a lookup on that key.
Then no special syntax is needed because the standard `alist!x` would work, as it expands into `(alist 'x)`.
Naturally, this means that you couldn't do a lookup in your alist with a number using the `!` syntax, but that might be OK for you if you aren't using numbers in keys in the alists that you want to use the `!` syntax with.
This option wouldn't return the alist value on an index access though, as it would continue to return the association pair.
Another option would be to create a new type (e.g. using `annotate`) and then have calling objects of that type do what you want (for example, in Anarki you could use `defcall`).