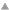A couple of days ago I found myself scratching my head over this terse definition of zip from anarki [1]: (def zip ls
(apply map list ls))
(test-iso "zip merges corresponding elements of lists"
'((1 2 3) (2 4 6) (3 6 9))
(zip '(1 2 3) '(2 4 6 7) '(3 6 9)))
When I understood it and replaced the naive recursive implementation in my toolbox, I found myself wondering if there's a better implementation for zipmax, which doesn't stop when the shortest list runs out: (def zipmax l
(if (some acons l)
(cons (map car l)
(apply zipmax (map cdr l)))))
(test-iso "zipmax returns as many elements as the longest list"
'((1 2) (3 4) (5 6) (nil 8))
(zipmax '(1 3 5) '(2 4 6 8)))
(Please feel free to suggest better names or implementations, as before - http://arclanguage.org/item?id=11111)Why is zipmax useful? It allows us to construct nctx. (def nctx(n l)
(apply zipmax (cdrs (- n 1) l)))
(def cdrs(n l)
(if (is n 0)
(list l)
(cons l (cdrs (- n 1) (cdr l)))))
(test-iso "nctx slides a window over a list"
'((1 2 3) (2 3 4) (3 4 nil) (4 nil nil))
(nctx 3 '(1 2 3 4)))
(test-iso "cdrs"
'((1 2 3) (2 3) (3))
(cdrs 2 '(1 2 3)))
nctx is surprisingly useful anytime you want to iterate over a list in a stateful way, with each iteration aware of the current and previous element, or current and next, etc.--- An illustration of nctx Here's how I use nctx to build a context-sensitive tokenizer.[2] In english, certain characters may or may not mark word boundaries depending on context. For example, single quotes shouldn't break up words when used as apostrophes, but shouldn't attach themselves to touching words within quoted sentences. (mac conscar(a l)
`(= ,l (cons (cons ,a (car ,l)) (cdr ,l))))
(def partition-words(s)
(unless (blank s)
(withs (firstchar (s 0)
ans (list (list firstchar))
state (charclass firstchar))
(each (last curr next) (nctx 3 (coerce s 'cons))
(if curr
(let newstate (charclass curr)
(if (is newstate 1)
(if (or (whitec last) (whitec next))
(= newstate 0)
(= newstate 2)))
(if
(is newstate state) (conscar curr ans)
(push (list curr) ans))
(= state newstate))))
(rev:map [coerce (rev _) 'string] ans))))
(with (NEVER-WORD* ";\"![]() \n\t\r"
MAYBE-WORD* ".,'=-/:&?")
(def charclass(c)
(let c (coerce c 'string)
(if
(posmatch c NEVER-WORD*) 0
(posmatch c MAYBE-WORD*) 1
2))))
So anyway, I'd love people's comments on this ball of parens. Is there an idiomatic or cheaper (in conses) non-recursive definition of zipmax? A better name for any of these functions?--- Footnotes: [1] rntz finally helped me figure it out: Apply right-associatively conses extra args together to form the list. (test-iso "apply strips outermost parens from last arg"
(list 3 '(1 2) '(3 4))
(apply list 3 '((1 2) (3 4))))
[2] PG's bayesian spam filter (http://paulgraham.com/better.html) uses a similar tokenizer, but it's described to only allow periods and commas within words. Here I permit other characters as well to match how humans read english: ' for apostrophes, - for hyphens, /=?& for urls, and : for timestamps. I couldn't find any scenarios where these characters should form word partitions without adjoining whitespace. Am I missing something?--- Appendix: Some more automated tests (anarki/lib/arctap.arc) (test-iso "nctx trivial"
'((1 nil))
(nctx 2 '(1)))
(test-iso "partition-words should partition along whitespace"
'("abc" " " "def")
(partition-words "abc def"))
(test-iso "partition-words should partition along punctuation"
'("abc" ", " "def")
(partition-words "abc, def"))
(test-iso "partition-words should intelligently partition along punctuation 1"
'("abc" " - " "def")
(partition-words "abc - def"))
(test-iso "partition-words should intelligently partition along punctuation 2"
'("abc-def")
(partition-words "abc-def"))
(test-iso "partition-words should intelligently partition along punctuation 3"
'("abc" " \"" "def" "\"")
(partition-words "abc \"def\""))
|