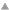I'd use a different name for nctx because I don't know what it's supposed to mean. You define it as a sliding window, so I call it windows (alternatively sliding-windows, but that's a bit longer).
I notice that it conses a lot for cdrs, which is ultimately useless since (cdrs (- n 1) l) is just used in an apply. Also, the stateful iteration remark reminded me of the discussion at http://arclanguage.org/item?id=11104. So, without studying zipmax at all, I rewrote nctx (in vanilla Arc) using reclist:
(def windows (n xs)
(accum a
(reclist [do (a:firstn n _) nil] xs)))
The next way I might try speeding it up is to inline firstn, which means we need a macro, but that seems hard to do at expansion time without passing a literal number instead of n. Plus, I think this definition strikes a nice balance between efficiency and self-containment (i.e., we need no new definitions).
I haven't figured out a way to simplify partition-words yet, but when I get a chance later I'll have a look. At first glance, I'd use symbols instead of 0, 1, and 2 for your character classes. e.g.,
(with (NEVER-WORD* ";\"![]() \n\t\r"
MAYBE-WORD* ".,'=-/:&?")
(def charclass(c)
(let c (coerce c 'string)
(if (posmatch c NEVER-WORD*)
'never
(posmatch c MAYBE-WORD*)
'maybe
'always))))
It's more readable simply because words have more meaning than numbers.
That was illuminating, thanks! That final definition of windows is awesome. I wrote these functions about six months ago, when I wasn't aware of reclist. Come to think of it, I still haven't used reclist before, so perhaps this thread should be called reclist not zip.
nctx => short for 'context of n'. For this post I deliberately tried to come up with three different perspectives on each function (description, name, test string) just to see what sticks.
Ah. I had guessed that, but it still seemed clunky. I'm liking sliding-window, but it's kind of long.
As for partition-words, it could be made clearer (less "ball of parens") with shorter definitions and more evenly distributed logic.
(conscar a l) is just (push a (car l)), so we can get rid of a macro.
Notice that charclass is used in two places: once for firstchar, and several times for any subsequent curr character. But each time it's called on curr, the newstate is set to something that's definitely not 'maybe (renamed per my previous comment). So it seems that this logic could be moved into charclass itself.
(with (NEVER-WORD* ";\"![]() \n\t\r"
MAYBE-WORD* ".,'=-/:&?")
(def charclass (c prev next)
(let c (coerce c 'string)
(if (posmatch c NEVER-WORD*)
'never
(posmatch c MAYBE-WORD*)
(if (or (whitec prev) (whitec next))
'never
'always)
'always))))
This handles the curr characters. Before handling firstchar, we can simplify thus:
Changes: (1) It's not a big deal, but Arc tends toward lowercase. (2) Since your variables were named like globals (i.e., with asterisks), I made them actually global. There's nothing wrong with the with block, but if you use that you probably shouldn't put asterisks after the names. (3) You can use find instead of the coerce & posmatch stuff. (4) I use prev instead of last to avoid confusion because Arc already defines a last function.
With this abstracted, we can analyze how state changes. Specifically, we see that firstchar can give a 'maybe result, though no other character can. I suspect this is a flaw in the logic, but preserved it anyway. It's cleaner to separate these two cases into their own functions, so I write
(= never-word* ";\"![]() \n\t\r"
maybe-word* ".,'=-/:&?")
(def charclass (c)
(if (find c never-word*)
'never
(find c maybe-word*)
'maybe
'always))
(def charstate (c prev next)
(caselet class (charclass c)
maybe (if (or (whitec prev) (whitec next))
'never
'always)
class))
Updating gives us the program:
(= never-word* ";\"![]() \n\t\r"
maybe-word* ".,'=-/:&?")
(def sliding-window (n xs)
(accum a
(a (firstn n xs))
(whilet xs (cdr xs)
(a (firstn n xs)))))
(def charclass (c)
(if (find c never-word*)
'never
(find c maybe-word*)
'maybe
'always))
(def charstate (c prev next)
(caselet class (charclass c)
maybe (if (or (whitec prev) (whitec next))
'never
'always)
class))
(def partition-words (s)
(unless (blank s)
(with (ans (list:list:s 0) state (charclass s.0))
(each (prev curr next) (sliding-window 3 (coerce s 'cons))
(when curr
(let newstate (charstate curr prev next)
(if (is newstate state)
(push curr (car ans))
(push (list curr) ans))
(= state newstate))))
(rev:map [coerce (rev _) 'string] ans))))
That's as far as I got. I think the code's clearer, but I'm not even sure how the original was supposed to work. For example, yours and mine both give these results:
arc> (partition-words "this slash / has spaces")
("this" " " "slash" " / " "has" " " "spaces")
arc> (partition-words "/ this slash doesn't")
("/" " " "this" " " "slash" " " "doesn't")
arc> (partition-words "My parents' car is fast. It's all like 'vroom'.")
("My" " " "parents" "' " "car" " " "is" " " "fast" ". " "It's" " " "all" " " "like" " '" "vroom'.")
But I defer to your judgment, since it's your program. ;)
Very nice, thanks. I'm leaning toward windows as well. nctx is shorter, but it's not clear I use it often enough to justify the terseness.
Those single quote issues on the last line are def bugs, thanks.
partition-words isn't a tokenizer, it partitions the string along word boundaries. Hence the tokens containing spaces and punctuation. You can easily extract tokens with a single keep, but I found it useful to be able to easily recombine the partitions to reconstruct the original string.